Home | Projects | Notes > Computer Architecture & Organization > Introduction to Pipelining
Introduction to Pipelining
What is Pipelining?
The basic concept of pipelining is to execute independent instructions in a continuous, orderly, and somewhat overlapped manner to improve the overall CPU performance.
One of many techniques to improve the Instruction-Level Parallelism (ILP) in a processor.
Analogy - Computer Assembly Line
A simple example is the factory assembly line for a computer which takes 1 person 100 minutes to build one computer. Let’s divide the assembly process into 5 subtasks (A to E) which take exactly the same amount of time; 20 minutes. Once the pipeline is full, a computer is finished every cycle; 20 minutes. It still takes same amount of time to build; 100 minutes each.
xxxxxxxxxx6120m 20m 20m 20m 20m 20m 20m 20m 20m2- ---- ---- ---- ---- ---- ---- ---- ---- ----31 A B C D E42 A B C D E53 A B C D E64 A B C D EPros: Faster, specialized steps
Cons: More resources are needed (people, workstations, tools)
The same principles apply to CPUs as well (with some additional complexity). By overlapping the stages and executing the instructions in parallel, it will look like one instruction completes execution once every clock-cycle. Of course the pipeline has to fill-up first.
Pipelining came from RISC efforts but is now used by almost every modern processor; CISC adopted it. Yet another example of the blurring of the lines between RISC and CISC.
What is the effect on the hardware?
Redundant hardware will be necessary so it can be used by the different stages at the same time. (e.g., The PC increment during the Instruction Fetch cannot use the ALU that is used for the Execution stage. However it can be done by adding an extra adder to the PC so it can increment itself without the help of ALU.)
What is the effect on the software?
There are cases where an operand read can happen prior to or at the same time as the operand write. (Can get old data.) The assembler has to know about this and reorganize the code to make sure this does not happen.
Various Pipelines
Five-Stage Pipeline (Standard)
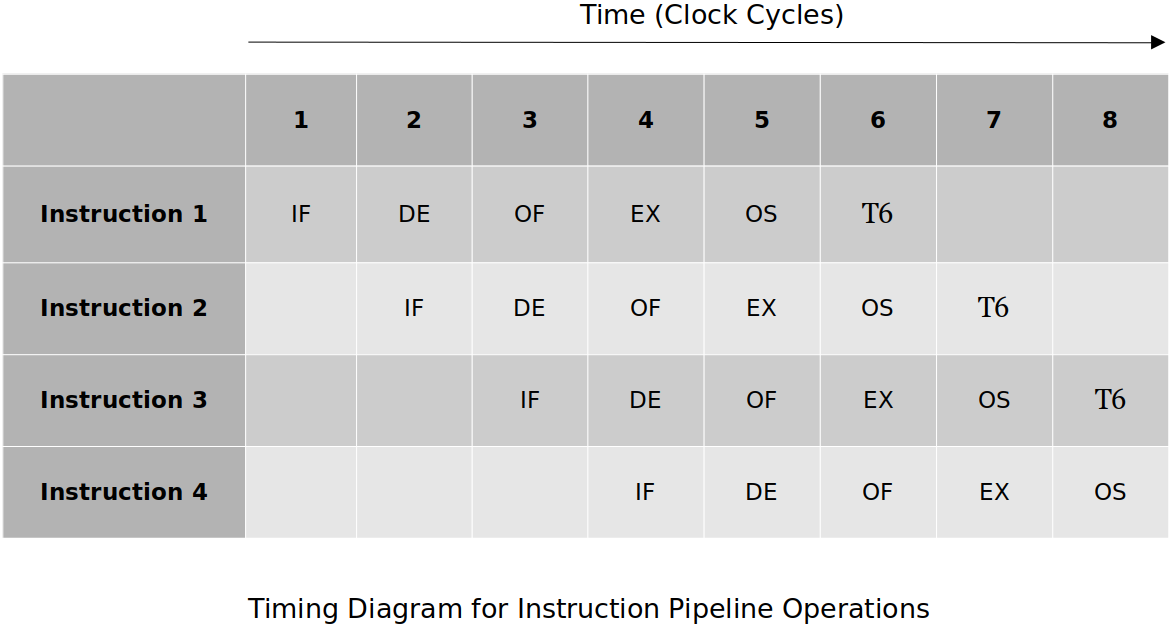
A simplified ARM11 pipeline, standard pipeline or what we as computer science students are expected to know if asked about a pipeline.
IF (Instruction Fetch)
Read the instruction
add r0, r1, r2from the system memory and increment the program counter.
ID (Instruction Decode)
Decode the instruction read from memory during the previous phase. The nature of the instruction decode phase is dependent on the complexity of the instruction set.
OF (Operand Fetch)
The operands specified by the instruction are read from resisters
r1andr2in the register file and latched into flip-flops.EX (Execute)
The operations specified by the instruction is carried out.
OS (Operand Store)
The result of the execution phase is written into the operand destination in main memory. This may be an on-chip register or a location in external memory. In this case the result is stored in register
r0.
Typically each of these stages take one clock-cycle to execute.
Not all instructions require all 5 stages. (e.g., a
CMPdoes not have the OS stage.)
Another Five-Stage Pipeline
In this case, Instruction Fetch (IF) also decodes the instruction.
Instruction Fetch
Operand Read
Execute
Memory
Write Operand
There may be separate pipelines for different instructions in a single system. (e.g., Floating point instructions may have their own pipeline which tends to be much longer.)
Four-Stage Pipeline
Stages
Instruction Fetch
Operand Read
Execute
Write Operand
Shorter pipelines are easier to demonstrate the issues with pipelines. The issues get worst with longer (more) pipeline stages.
Speedup Ratio
The performance of a pipeline is expressed in terms of its speedup ratio.
With the pipeline, the first instruction (out of
When
When
Examples:
20 instruction with 5 stages:
100 instruction with 5 stages:
10000 instruction with 5 stages:
Basically what these examples are trying to show is that once you get to the point of executing an infinite number of executions, your speedup is equal to the number of the stages in the pipeline.
In theory, once the pipeline is full, a new operation is completed every clock cycle. But this cannot be achieved all the time due to:
Branches
Data dependencies