Home | Projects | Notes > Computer Architecture & Organization > Pipeline Hazards
Pipeline Hazards
Pipeline Hazards
A pipeline hazard occurs when the pipeline, or some portion of the pipeline, must stall because conditions do not permit continued execution. Such a pipeline stall is also referred to as pipeline bubble.
Three types of hazards:
Structural hazard (or resource hazard)
Data hazard (or pipeline data hazard)
Control hazard (or branch hazard)
Structural Hazard (a.k.a. Resource Hazard)
A structural hazard occurs when two (or more) instructions that are already in the pipeline need the same resource simultaneously. The result is that the instructions must be executed in serial rather than parallel for a portion of the pipeline.
For example, memory can be a structural hazard if two instructions attempt to access it at the same time and it cannot grant simultaneous access.
Another example is when multiple instructions are ready to enter the execute instruction phase and there is a single ALU. One solution to such structural hazards is to increase available resources, such as having multiple ports into main memory and multiple ALU units.
Structural hazards have to be taken care of in the design time.
Data Hazard (a.k.a. Pipeline Data Hazard)
A data hazard occurs when the processing of one instruction depends on the data created by a previous instruction that is still in the pipeline. To maintain correct operation, the pipeline must stall for one or more clocks cycles which results in inefficient pipeline usage.
To prevent data hazards, special hardware is used to forward or bypass the stages to provide the results sooner.
Three types of data hazards:
Read after write (RAW), or true data dependency
An instruction modifies a register or memory location and a succeeding instruction reads the data in that memory or register location. A hazard occurs if the read takes place before the write operation is complete.
For example:
xxxxxxxxxx21add r0, r1, r22sub r4, r0, r5 @ r0 will not be ready in time for this calculation.
Write after read (WAR), or anti data dependency
An instruction reads a register or memory location and a succeeding instruction writes to the location. A hazard occurs if the write operation completes before the read operation takes place.
For example:
xxxxxxxxxx21add r1, r2, r32sub r2, r4, r5WAR hazard cannot occur in most systems. If the instructions are reordered (e.g., to delay branches) then this presents a problem!
Write after write (WAW), or output dependency
Two instructions both write to the same location. A hazard occurs if the write operations take place in the reverse order of the intended sequence.
For example:
xxxxxxxxxx21add r1, r2, r32sub r1, r4, r5WAW hazard is very unlikely to happen in a single core processor. It is more of a multi-core processor issue.
Can happen with superscalar processors that perform out-of-order execution. In “Operating Systems” this is also called a race condition. When the value of a variable is dependent on the order of execution of the instructions and the last instruction to execute wins by having its value stored.
Control Hazard (a.k.a. Branch Hazard)
A control hazard occurs when a branch is taken and all the partially executed instructions in the pipeline have to be thrown away (or flushed, squashed). This happens because when a branch instruction (to be taken) is fetched, its target address is not known until it is in the execute stage in the pipeline. During that time (i.e., IF ~ EX), the subsequent instructions are pushed into the pipeline only to be wasted.
Mitigating Pipeline Hazards
Mitigating Data Hazards
Data dependency arises when the outcome of the current operation is dependent on the result of a previous instruction that has not yet been executed to completion.
The most important form of data hazard is RAW, where a read operation takes place after a write.
Two solutions to mitigate the aspect of data hazard:
Bubbles (primitive)
Internal data forwarding (advanced)
1. Introducing Bubbles
Consider,
xxxxxxxxxx61@ X = (A + B) AND (A + B - C)2@ assume A, B, C, X and two temporary values, T1 and T2, are in registers34add T1, A, B @ [T1] ← [A] + [B] ; T1 will not be available immediately5sub T2, T1, C @ [T2] ← [T1] - [C] ; uses T1 before the instruction 1 has committed it to memory6and X, T1, T2 @ [X] ← [T1] · [T2]; uses T2 before the instruction 1 has committed it to memoryHow to fix this?
Bubbles can be introduced into the pipeline while the instructions
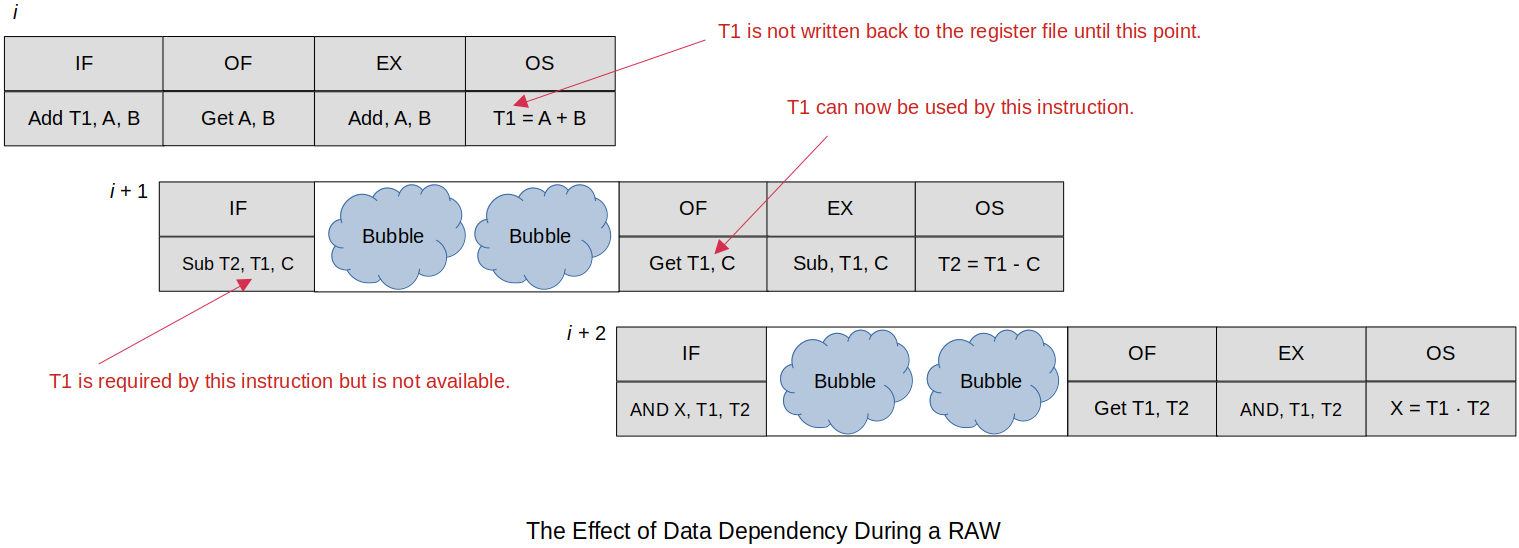
However, this is not what pipelines are for! This can be improved in the hardware by using internal data forwarding.
2. Internal Data Forwarding
Internal data forwarding is a mechanism to reduces the stalls due to data dependency, it uses hardware technique to forward the result of interstage buffer register (IBR) to next instruction’s buffer register.
Consider,
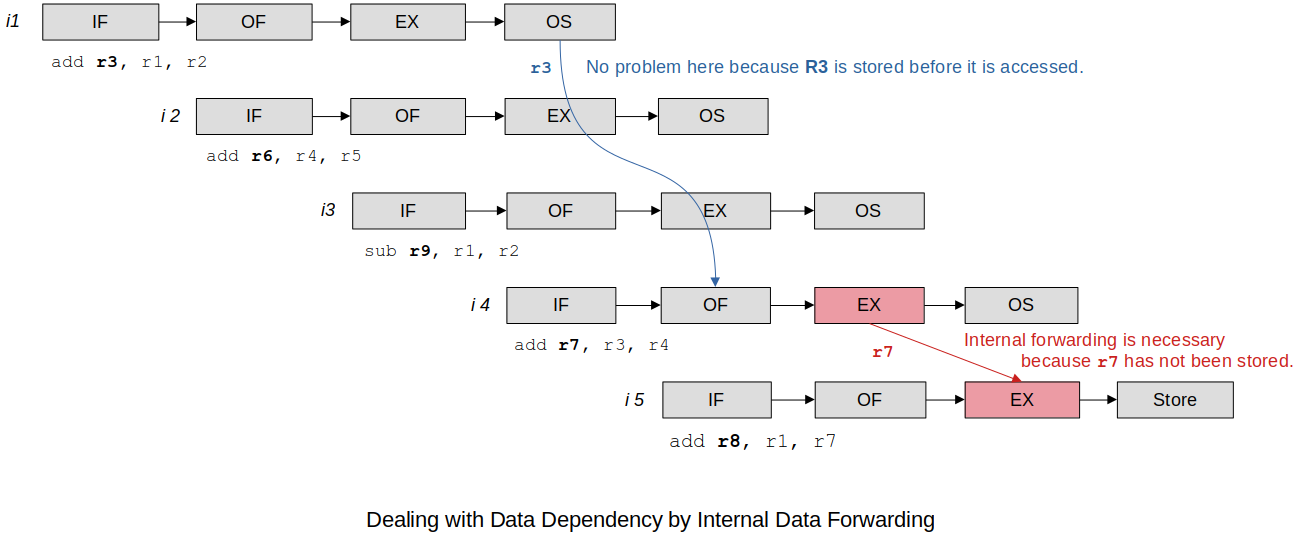
xxxxxxxxxx51add r3, r1, r2 @ [r3] ← [r1] + [r2]2add r6, r4, r5 @ [r6] ← [r4] + [r5]3add r9, r1, r2 @ [r9] ← [r1] + [r2]4add r7, r3, r4 @ [r7] ← [r3] + [r4] ; RAW harzard because r7 is reuqired by the next instruction5add r8, r1, r7 @ [r8] ← [r1] + [r7]Instruction 4 generates a destination operand
r7that is required as a source operand by the next instruction. If the processor were to read the source operand requested by instruction 5 from the register file, it would see the old value ofr7.How to fix this?
By means of internal data forwarding the processor transfers
R7from instruction 4’s execution unit directly to the execution unit of instruction 5. (When the issue is detected the internal forwarding hardware provides the right data to the instruction.)
Mitigating Control Hazard (Branch Hazard)
It is known that branches take up 5 ~ 30% of the instructions in any program. (e.g., Unconditional branches, conditional branches, indirect branches, procedure calls, procedure returns). So, it is very important that they are correct and efficient.
The following are some of the solutions that have been proposed for mitigating aspects of control hazards:
Pipeline stall
Delayed branch
Branch prediction
1. Pipeline Stall
Freeze the pipeline until the branch outcome and target are known, then proceed with fetch. Thus, every branch instruction incurs a penalty equal to the number of stall cycles. This solution is unsatisfactory if the instruction mix contains many branch instructions, and/or the pipeline is very deep.
2. Delayed Branch
Delayed branch is reordering of the instructions in such a way that the instruction immediately following a branch is always executed. This avoids stalling the pipeline while the branch condition is evaluated, thus keeping the pipeline full and minimizing the effect of conditional branches on processor performance.
xxxxxxxxxx51@ original code2add r3, r2, r13add r5, r4, r6 @ not dependent on the following branch, will be executed 100% anyways4b N5add r7, r8, r9xxxxxxxxxx51@ reordered code2add r3, r2, r13b N4add r5, r4, r6 @ gets executed in the "branch delay slot"5add r7, r4, r6Sections in the code to look for the instructions to fill the branch delay slot:
Before the branch instruction (Best choice, always improves performance)
Target address (Only meaningful when branch taken)
Fall through (Only meaningful when not taken)
Unfortunately, it's not always possible to reorder the code in such a way that the instruction immediately following a branch is always executed. It is said that 70% of the time, an instruction is found to fill the branch delay slot. If the compiler fails to find such an instruction, it must introduce a no operation (
NOP) instruction after the branch and accept the inevitability of a stall (or bubble).xxxxxxxxxx51add r3, r2, r12add r5, r4, r63b N4NOP @ no operation ("branch delay slot")5add r7, r8, r9This really slows down the pipeline. The more stages the pipeline has the more
NOPs that have to be added and the bigger the the slow-down in the pipeline.
3. Branch Prediction
Branch prediction is an approach to computer architecture that attempts to mitigate the costs of branching. The processor looks ahead in the instruction code fetched from memory and takes an educated guess if the branch will or will not be taken.
Two types of branch prediction:
Static branch prediction
Dynamic branch prediction (Branch guess are determined at runtime and will change over time)
Prediction mechanisms works well with unconditional branches like:
xxxxxxxxxx31B Loop @ unconditional branch; this branch will be taken 100%23Loop:Conditional branches pose a problem:
xxxxxxxxxx41bne Loop @ conditional branch; CCR flags setting affects the subsequent instructions2...34Loop:
Data Hazard Analysis Examples
Example 1
xxxxxxxxxx101Instruction R0 R1 R2 R3 R4 R5 R6 R7 R82================== == == == == == == == == ==3I1: ADD R0, R1, R2 W R R4I2: ADD R3, R1, R2 R R W5I3: ADD R4, R1, R3 R R W6I4: ADD R5, R2, R3 R R W7I5: ADD R6, R1, R0 R R W8I6: ADD R7, R7, R2 R R9W10I7: ADD R8, R6, R0 R R WRAW
R
R
R
WAR
R
WAW
None
Example 2
xxxxxxxxxx71Instruction R0 R1 R2 R3 R4 R5 R6 R7 R82================== == == == == == == == == ==3I1: ADD R2, R0, R1 R R W4I2: ADD R5, R3, R4 R R W5I3: SUB R8, R0, R1 R R W6I4: ADD R6, R2, R3 R R W7I5: ADD R7, R0, R6 R R WRAW
R
R
WAR
None
WAW
None
Example 3
xxxxxxxxxx71Instruction R0 R1 R2 R3 R4 R5 R6 X2================== == == == == == == == ==3I1: ADD R5, R0, R1 R R W4I2: MUL R6, R2, R5 R R W5I3: SUB R5, R3, R6 R W R6I4: DIV R6, R5, R4 R R W7I5: STR R7, R0, R6 R WRAW
R
R
WAR
R
R
WAW
R
R