Home | Projects | Notes > Data Structures & Algorithms > Hash Tables
Hash Tables
Why is Map Necessary?
In storing key-value pairs,
Arrays limit the key to integer values which will be used as an index.
41a1[1] = 3;2a2[3] = "three";3a3[0] = 'a';4...Maps can store any pairs of any types.
41m1["three"] = 32m2[5] = 23m3['A'] = 'a'4...
C++ Built-in Maps
std::map(header:<map>)Implemented using binary search tree (BST). Due to the nature of the BST, it is ordered map.
Iterator will iterate through the elements based on key order.
The time complexity of all the functions is O(log n).
std::unordered_map(header:<unordered_map>)Implemented using hash table.
Keys are unique.
It is NOT guaranteed that the iterator will iterate through the elements based on key order.
Time complexity of all the functions is O(1).
Functions:
insert(),at(),size(),erase(), etc.
Hash Tables (Hash Maps)
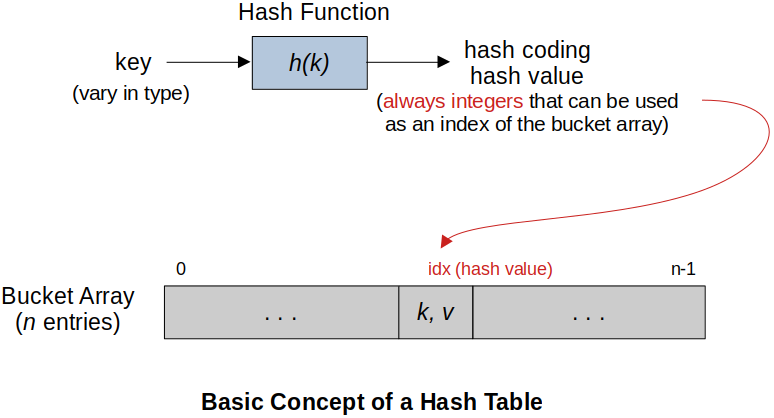
Hash tables support one of the most efficient types of searching: hashing.
A hash table consists of an array (a.k.a. bucket array) in which data is accessed via a special index called key.
The primary idea behind a hash table is to establish a mapping between the set of all possible keys and positions in the array using a hash function.
A hash function accepts a key and returns its hash coding, or hash value.
Keys vary in type, but hash codings are always integers.
Two components of hash functions:
Hash code (converts a key to an integer)
21IF key = 'A', hash code = convert character to ascii2THEN h('A') = 97Compression function (scales the converted integer to a valid index of the bucket array)
31IF bucket array can contain 26 entries2THEN good compression function can be '% 26' since it scales whatever the hash3value is to an integer (hash coding, or hash value) ranging 0-25.
A good hash function produces wide-spread hash values as randomly as possible within the valid range of integers. Some well-known hash functions:
Base-26
131// e.g., A hash function which gets passed a 4-character string and returns a2// hash index as an int. Assume the table size is defined as 'ts'.34int hashBase26(char *key, int ts)5{6int index;7index = ((key[0] - 'A' + 1) * pow(26,3) +8((key[1] - 'A' + 1) * pow(26,2) +9((key[2] - 'A' + 1) * pow(26,1) +10((key[3] - 'A' + 1) * pow(26,0) +1112return index % ts;13}Folding
101// e.g., A hash function using Folding23int hashFolding(char *key, int ts)4{5int index;6index = ((key[0] - 'A' + 1) * (key[1] - 'A' + 1)) +7((key[2] - 'A' + 1) * (key[3] - 'A' + 1));89return index % ts;10}Middle Squaring
91// e.g., A hash function using Middle Squaring23int hashMiddleSquaring(char *key, int ts)4{5int index;6index = ((key[1] - 'A' + 1) * (key[2] - 'A' + 1));78return index % ts;9}Division Method
A good general approach:
Select a table size that is a prime number
Translate the key into an integer
Divide Key / M = Q with remainder R
Use R as a hash value
Use max(1, Q) as the probe in/decrement auxiliary hash function (double hashing)
Collision Handling Techniques
Closed Addressing (Closed Hashing)
A key is always stored in the bucket it is hashed to.
Collisions are handled by using separate data structure on a per-bucket basis.
Arbitrary number of keys per bucket.
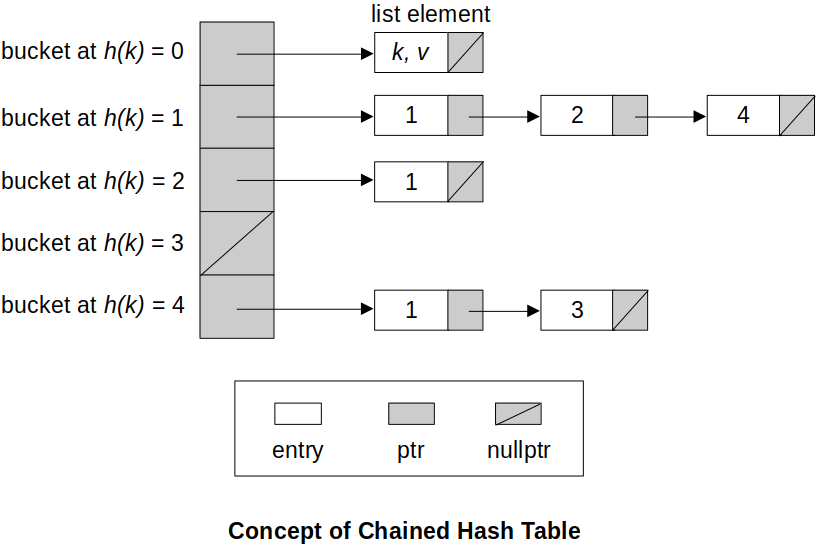
e.g., Chained Hash Table (Separate Chaining)
Consists of an array of linked lists.
Each list forms a bucket in which we place all elements hashing to a specific position in the array.
Performs as good as open addressing techniques.
Open Addressing (Open Hashing)
At most one key per bucket
Collisions are handled by searching for another empty buckets within the hash table array itself. This searching is handled by the hash function
Some well-known open addressing techniques (depending on the choice of
linear probing
Although it is simple to implement, it is prone to primary clustering (cluster developed due to the local popular index).
quadratic probing
This alleviates the primary clustering to some extent.
double hashing
Two auxiliary hash functions should be carefully chosen so that the elements are distributed in a uniform and random manner.
Implementation (C++) - Chained Hash Table
Header (chtable.hpp)
x
1
4
8class pair 9{10public:11 pair(const std::string &key, const int val) : k(key), v(val) {}12
13 std::string k;14 int v;15};16
17class chtable18{19public:20 chtable() : bucket_arr(NUM_OF_BUCKETS) {}21 void insert(const std::string &key, const int val);22 bool get(const std::string &key, int &val_out) const;23 bool contains(const std::string &key) const;24 void remove(const std::string &key);25 void print() const;26
27private:28 static const int NUM_OF_BUCKETS = 11; // prime number is good29 std::vector<std::list<pair>> bucket_arr;30
31 int hash(const std::string &key) const;32};33
34Source (chtable.cpp)
851
4void chtable::insert(const std::string &key, const int val)5{6 int i = hash(key);7
8 for (pair &p : bucket_arr[i])9 {10 if (p.k == key)11 {12 p.v = val; // update value13 return;14 }15 }16
17 // NOTE: here push_back(key, val) won't work!18 bucket_arr[i].emplace_back(key, val); // insert a new pair19}20
21bool chtable::get(const std::string &key, int &val_out) const22{23 int i = hash(key);24
25 for (const pair &p : bucket_arr[i])26 {27 if (p.k == key)28 {29 val_out = p.v;30 return true;31 }32 }33
34 // key not found35 return false;36}37
38bool chtable::contains(const std::string &key) const39{40 int dummy;41 return get(key, dummy);42}43
44void chtable::remove(const std::string &key)45{46 int i = hash(key);47 auto &bucket = bucket_arr[i];48
49 for (auto it = bucket.begin(); it != bucket.end(); ++it)50 {51 if (it->k == key)52 {53 bucket.erase(it);54 return;55 }56 }57}58
59void chtable::print() const60{61 for (int i = 0; i < NUM_OF_BUCKETS; ++i)62 {63 std::cout << i << ": ";64
65 for (const pair &p : bucket_arr[i])66 {67 std::cout << "{" << p.k << ", " << p.v << "} ";68 }69 70 std::cout << std::endl;71 }72}73
74// private function75int chtable::hash(const std::string &key) const76{77 int sum = 0;78
79 for (char c : key)80 {81 sum += c; // add ascii values82 }83
84 return sum % NUM_OF_BUCKETS;85}L19: Revisit why you can't use
push_back(key, val)there!
Test Driver
291
4int main(int argc, char *argv[])5{6 chtable ht;7
8 ht.insert("apple", 10);9 ht.insert("banana", 20);10 ht.insert("grape", 30);11 ht.insert("banana", 25); // update12
13 ht.print();14 std::cout << std::endl;15
16 int value;17 if (ht.get("banana", value))18 {19 std::cout << "banana -> " << value << std::endl;20 }21
22 std::cout << std::endl;23
24 ht.remove("apple");25 std::cout << "After removing 'apple':" << std::endl;26 ht.print();27
28 return 0;29}2610:21:32: {apple, 10}43:54: {banana, 25}65:76:87:98:109:1110: {grape, 30}12
13banana -> 2514
15After removing 'apple':160:171:182:193:204: {banana, 25}215:226:237:248:259:2610: {grape, 30}
Chained Hash Table 1 (C++)
Interface
491//==============================================================================2// File : hash_table.h3// Brief : Interface for Hash Table4// Author : Kyungjae Lee5// Date : Jul 31, 20236//7// Note : It is known that when the number of bucket array elements is a 8// prime number, the (key, value) pairs are distributed more 9// randomely (i.e., less collision).10//==============================================================================11
12
15
19using namespace std;20
21// Class for hash table nodes22class Node23{24public:25 string key;26 int value;27 Node *next;28
29 Node(string key, int value); // Constructor30};31
32// Class for hash table 33class HashTable34{35public:36 HashTable(int size); // Constructor37 ~HashTable(void); // Destructor38 void printHashTable(void); // Prints all the nodes in the hash table39 void insert(string key, int value); // Insert a node into the hash table40 int lookup(string key); // Looks up a value by key from the hash table41 vector<string> keys(void); // Returns a vector of keys in the hash table42 int hash(string key); // Hash function43
44private:45 int bucketArrSize; // Bucket array size (prime number recommended)46 vector<Node *> bucketArr; // Bucket array47};48
49// HASH_TABLE_HImplementation
1641//==============================================================================2// File : hash_table.cpp3// Brief : Implementation of Hash Table4// Author : Kyungjae Lee5// Date : Jul 31, 20236//7// Note : It is known that when the number of bucket array elements is a 8// prime number, the (key, value) pairs are distributed more 9// randomely (i.e., less collision).10//==============================================================================11
12
14using namespace std;15
16//------------------------------------------------------------------------------17// Implementation of Node class interface18//------------------------------------------------------------------------------19
20// Constructor21// T = O(1)22Node::Node(string key, int value)23{24 this->key = key;25 this->value = value;26 next = nullptr;27} // End of Node class constructor28
29//------------------------------------------------------------------------------30// Implementation of Hash Table class interface31//------------------------------------------------------------------------------32
33// Constructor34// T = O(1)35HashTable::HashTable(int size)36{37 bucketArrSize = size;38 bucketArr.reserve(size); // Size of prime number recommended39} // End of Hash Table class constructor40
41// Destructor42// T = O(n)43HashTable::~HashTable(void)44{45 // Destroy all the nodes46 Node *delNode, *head;47
48 for (int i = 0; i < bucketArrSize; i++)49 {50 delNode = bucketArr[i];51 head = bucketArr[i];52
53 while (head)54 {55 head = head->next;56 delete delNode;57 delNode = head;58 }59 }60
61 // Destory the bucket array62 bucketArrSize.~vector();63} // End of Desctructor64
65// Prints all the nodes in the hash table66// T = O(n)67void HashTable::printHashTable(void)68{69 for (int i = 0; i < bucketArrSize; i++)70 {71 cout << i << ": ";72 if (bucketArr[i])73 {74 Node *temp = bucketArr[i];75 while (temp)76 {77 cout << "(" << temp->key << ", " << temp->value << "} ";78 temp = temp->next;79 }80 }81 cout << endl;82 }83} // End of printHashTable84
85// Inserts a node into the hash table (Closed addressing; chaining)86// T = O(1)87void HashTable::insert(string key, int value)88{89 int index = hash(key);90 Node *newNode = new Node(key, value);91 92 if (bucketArr[index] == nullptr)93 {94 // No collision detected, so simply insert the new node95 bucketArr[index] = newNode;96 }97 else98 {99 // Collision detected100 Node *temp = bucketArr[index];101
102 // Find the last node of the chain103 while (temp->next != nullptr)104 temp = temp->next;105
106 // Insert the new node after the last node in the chain107 temp->next = newNode;108 }109} // End of insert110
111// Looks up a value by key from the hash table112// T = O(1)113int HashTable::lookup(string key)114{115 int index = hash(key);116 Node *temp = bucketArr[index];117 118 // Search the key119 while (temp)120 {121 if (temp->key == key)122 return temp->value;123 124 temp = temp->next;125 }126 127 // Key is not found, return 0128 return 0;129} // End of lookup130
131// Returns a vector of keys in the hash table132// T = O(n)133vector<string> HashTable::keys()134{135 vector<string> allKeys;136 for (int i = 0; i < bucketArrSize; i++)137 {138 Node *temp = bucketArr[i];139
140 while (temp)141 {142 allKeys.push_back(temp->key);143 temp = temp->next;144 }145 }146
147 return allKeys;148} // End of keys149
150// Hash function151int HashTable::hash(string key)152{153 int hash = 0;154 for (int i = 0; i < key.length(); i++)155 {156 int ascii = key[i];157
158 // Multiply by 23, a prime number, to make the result more random159 // Divide by bucketArrSize to normalize the result160 hash = (hash + ascii * 23) % bucketArrSize;161 }162
163 return hash;164} // End of hashTest Driver
451//==============================================================================2// File : main.cpp3// Brief : Test driver for Hash Table4// Author : Kyungjae Lee5// Date : Jul 31, 20236//==============================================================================7
8
11using namespace std;12
13int main(int argc, char *argv[])14{15 // Create a hash table16 HashTable *ht = new HashTable(7);17 18 // Insert elements19 ht->insert("nails", 100);20 ht->insert("tile", 50);21 ht->insert("lumber", 80);22 ht->insert("bolts", 200);23 ht->insert("screws", 140);24
25 // Print hash table26 ht->printHashTable();27
28 // Create a vector of keys present in the hash table29 vector<string> allKeys = ht->keys();30
31 cout << endl;32
33 // Print the keys34 for (auto key : allKeys)35 cout << key << " ";36
37 cout << endl;38
39 cout << "tile: " << ht->lookup("tile") << endl;40
41 // Destroy the hash table42 delete ht;43
44 return 0;45}1010: 21: 32: 43: (screws, 140} 54: (bolts, 200} 65: 76: (nails, 100} (tile, 50} (lumber, 80} 8
9screws bolts nails tile lumber 10tile: 50
Chained Hash Table 2 (C++)
For the ease of implementation, key will be string type, and value will be template.
Interface
601//==============================================================================2// File : chtbl.h3// Brief : Interface for chained hash table (in C++)4// Author : Kyungjae Lee5// Date : Dec 23, 20226//==============================================================================7
8
11
13using namespace std;14
15// Forward declaration16template <typename T> class CHTbl;17
18// Chained Hash Table Node class19template <typename T>20class CHTblNode21{22public:23 CHTblNode(string key, T value); // parameterized constructor 24 ~CHTblNode(); // parameterized constructor 25
26 // friend declaration27 template <typename> friend class CHTbl;28 29private:30 string key;31 T value;32 CHTblNode *next;33};34
35// Chained Hash Table36template <typename T>37class CHTbl38{39public:40 // function41 CHTbl(); // default constructor42 ~CHTbl(); // destructor43 int size(); // retrieve the total number of entries in the CHTbl 44 void insert(string key, T value); // insert an entry45 T remove(string key); // remove an entry by key46 T getValue(string key); // retrieve the value corresponding to the given key47 double getLoadFactor(); // retrieve the current load factor48 49private:50 // variable51 CHTblNode<T> **bucketArr; // bucket array52 int buckets; // max number of elements in the bucket array53 int count; // total number of entries in the CHTbl 54
55 // function56 int hash(string key); // convert key into the bucketArr index (hash value)57 void rehash(); // transfer entries to the resized bucket array58};59
60// CHTBL_HImplementation
2471//==============================================================================2// File : chtbl.c3// Brief : Implementation of chained hash table (in C++)4// Author : Kyungjae Lee5// Date : Dec 23, 20226//==============================================================================7
8
10// CHTblNode -------------------------------------------------------------------11
12// Parameterized constructor13// T = O(1)14template <typename T>15CHTblNode<T>::CHTblNode(string key, T value)16{17 this->key = key;18 this->value = value;19 next = nullptr;20} // end parameterized constructor21
22// destructor23// T = O(1)24template <typename T>25CHTblNode<T>::~CHTblNode()26{27 delete next; // recursively destroy the list28} // end destructor29
30// CHTbl -----------------------------------------------------------------------31
32// Default constructor33// T = O(1)34template <typename T>35CHTbl<T>::CHTbl()36{37 count = 0;38 buckets = 5; // set the initial number of buckets39 bucketArr = new CHTblNode<T>*[buckets];40} // end default constructor41
42// destructor43// T = O(n)44template <typename T>45CHTbl<T>::~CHTbl()46{47 // traverse each element of the bucketArr and delete lists associated with it48 // (just deleting the bucketArr won't delete these lists)49 for (int i = 0; i < buckets; i++)50 delete bucketArr[i];51
52 delete[] bucketArr; // delete the bucketArr53} // end destructor54
55// Retrieve the total number of entries in the CHTbl 56// T = O(1)57template <typename T>58int CHTbl<T>::size() 59{60 return count;61} // end size62
63// Insert an entry64// T = O(n/b) on average ; // T = O(1)65// - n: the total number of entries, b: the number of buckets, n/b: load factor66// - If we could keep n/b < 1, then T = O(1)67// - If this is the case, getValue and delete function will also run at O(1).68// - One way is to implement the number of buckets doubles the size every time the 69// load factor exceeds the properly chosen threshold. (e.g., n/b < 0.7)70// - When this happens, you need to 'rehash' all the exsisting keys because the hash71// value is dependent on the number of buckets. 72// - Hash function runs at O(l) where l is the length of the key, but it is ignored73// because l << n.74// - In the worst case, where the hash function is really bad such that it produces only75// one hash value for all the given keys, insert function will run at T = O(n). (i.e.,76// inserting and entry at the end of the list that contains all the n entries)77// But, this is unlikely to happen with good hash functions that are proven to work.78template <typename T>79void CHTbl<T>::insert(string key, T value)80{81 int bucketIndex = hash(key);82 CHTblNode<T> *curr = bucketArr[bucketIndex]; // pointer to traverse the list83
84 // search the list for the key85 while (curr)86 {87 // if the key was found88 if (curr->key == key)89 {90 curr->value = value; // just update the value91 return;92 }93
94 curr = curr->next;95 }96
97 // if key was not found insert a new node98 CHTblNode<T> *newNode = new CHTblNode(key, value); // create a node99 newNode->next = bucketArr[bucketIndex]; // insert at the head of the list100 bucketArr[bucketIndex] = newNode; // update the head101 count++; // increment count102 double loadFactor = (1.0 * count) / buckets; // update the load factor103
104 // if the load factor becomes greater than LOAD_FACTOR_THRESHOLD105 if (loadFactor > LOAD_FACTOR_THRESHOLD)106 rehash();107} // end insert108
109// Remove an entry by key110// T = O(1)111template <typename T>112T CHTbl<T>::remove(string key)113{114 int bucketIndex = hash(key);115 CHTblNode<T> *curr = bucketArr[bucketIndex]; // pointer to traverse the list116 CHTblNode<T> *prev = nullptr; // pointer to traverse the list117
118 // search the list for the key119 while (curr)120 {121 // if the key was found122 if (curr->key == key)123 {124 // remove the head from the list125 if (prev == nullptr)126 bucketArr[bucketIndex] = curr->next;127 // remove the node other than the head from the list128 else129 prev->next = curr->next;130
131 // delete the removed node132 T value = curr->value; // set aside the value to return133 curr->next = nullptr; // isolate curr to prevent recursive deletion134 delete curr; // deallocate memory space pointed at by curr135 count--; // decrement count136 137 return value;138 }139 140 prev = curr; // advance prev141 curr = curr->next; // advance curr142 }143
144 return 0; // '0' as a cross-type signal for key not found145} // end remove146
147// Retrieve the value corresponding to the given key148// T = O(1)149template <typename T>150T CHTbl<T>::getValue(string key)151{152 int bucketIndex = hash(key);153 CHTblNode<T> *curr = bucketArr[bucketIndex]; // pointer to traverse the list154
155 // search the list for the key156 while (curr)157 {158 // if the key was found159 if (curr->key == key)160 return curr->value;161
162 curr = curr->next; // advance curr163 }164
165 return 0; // '0' as a cross-type singal for key not found166} // end getValue167
168// Hash function - Convert key into bucketArr index (hash value)169// T = O(l) where l is the length of the key170template <typename T>171int CHTbl<T>::hash(string key)172{173 int hashCode = 0;174 int base = 37;175 int place = 1; // b^0 (ones') place, b^1s' place, b^2s' place and so on176
177 // step1: hash code (convert a key to an integer)178
179 // base-37180 // "abc" -> ('a' * 37^0) + ('b' * 37^1) + ('c' * 37^2)181 for (int i = 0; i < key.size(); i++)182 {183 hashCode += key[i] * place;184 place *= base;185 186 // Since place and hashCode grow fast, let's apply the property of modulo187 // operation and stay away from int overflow.188 // e.g., (a*b)%m = [(a%m)*(b%m)]%m189 hashCode %= buckets;190 base %= buckets;191 }192
193 // setp 2: compression (scale the converted integer to a valid bucketArr index)194 return hashCode % buckets;195 196} // end hash197
198// Transfer entries to the resized bucket array199// T = O(n)200template <typename T>201void CHTbl<T>::rehash()202{203 // create a new bucket array with double the size of the original one204 CHTblNode<T> **oldBucketArr = bucketArr;205 bucketArr = new CHTblNode<T>*[2 * buckets];206
207 // initialize the new bucket array208 for (int i = 0; i < 2 * buckets; i++)209 bucketArr[i] = nullptr;210
211 // update the number of buckets212 int oldBuckets = buckets;213 buckets *= 2;214
215 // reset count216 count = 0;217
218 // transfer the entries in the old bucket array to the new bucket array219 for (int i = 0; i < oldBuckets; i++)220 {221 CHTblNode<T> *curr = oldBucketArr[i]; // pointer to traverse the old bucket array222
223 while (curr)224 {225 string key = curr->key;226 T value = curr->value;227 insert(key, value); // entry gets inserted into the new bucket array228
229 curr = curr->next; // advance curr230 }231 }232
233 // deallocate the memory used for the lists associated the old bucket array234 for (int i = 0; i < oldBuckets; i++)235 delete oldBucketArr[i]; // recursively delete a list236
237 // deallocate the memory used for the old bucket array 238 delete[] oldBucketArr;239} // end rehash240
241// Retrieve the current load factor242// T = O(1)243template <typename T>244double CHTbl<T>::getLoadFactor()245{246 return (1.0 * count) / buckets;247} // end getLoadFactorTest Driver
731//==============================================================================2// File : chtbl_main.c3// Brief : Test driver for chained hash table (in C++)4// Author : Kyungjae Lee5// Date : Dec 23, 20226//==============================================================================7
8
11using namespace std;12
13int main(int argc, char *argv[])14{15 CHTbl<int> map; 16
17 cout << "Initial map info" << endl;18 cout << "size : " << map.size() << endl;19 cout << endl;20
21
22 // insert ("abc0", 1), ("abc1", 2), ("abc2", 3) ... , ("abc9", 10) into the map23 cout << "Insert (\"abc0\", 1), (\"abc1\", 2), ... , (\"abc9\", 10) "24 << "into the map" << endl;25 26 for (int i = 0; i < 10; i++)27 {28 // construct the key29 char c = '0' + i;30 string key = "abc";31 key = key + c;32 33 // construct the value34 int value = i + 1;35
36 // insert37 map.insert(key, value);38
39 // print the insertion status40 cout << "(" << key << ", " << value << ") inserted - ";41 cout << "load factor: " << map.getLoadFactor() << endl;42 }43
44 cout << "size : " << map.size() << endl;45 cout << endl;46
47 // remove entry48 cout << "Remove (\"abc1\", 2) and (\"abc6\", 7)" << endl;49 map.remove("abc1");50 map.remove("abc6");51
52 cout << "size : " << map.size() << endl;53 cout << endl;54
55 // printt the key, value pairs56 cout << "Print the key, value pairs (value of the removed entry : 0)" << endl;57 58 for (int i = 0; i < 10; i++)59 {60 // construct the key61 char c = '0' + i;62 string key = "abc";63 key = key + c;64
65 // print the key, value pairs66 cout << key << ", " << map.getValue(key) << endl;67 }68
69 cout << "size : " << map.size() << endl;70 cout << endl;71
72 return 0;73}311Initial map info2size : 0 <---- initial buckets: 53
4Insert ("abc0", 1), ("abc1", 2), ... , ("abc9", 10) into the map5(abc0, 1) inserted - load factor: 0.26(abc1, 2) inserted - load factor: 0.47(abc2, 3) inserted - load factor: 0.68(abc3, 4) inserted - load factor: 0.4 <---- rehash, buckets: 109(abc4, 5) inserted - load factor: 0.510(abc5, 6) inserted - load factor: 0.611(abc6, 7) inserted - load factor: 0.712(abc7, 8) inserted - load factor: 0.4 <---- rehash, buckets: 2013(abc8, 9) inserted - load factor: 0.4514(abc9, 10) inserted - load factor: 0.515size : 1016
17Remove ("abc1", 2) and ("abc6", 7)18size : 819
20Print the key, value pairs (value of the removed entry : 0)21abc0, 122abc1, 0 <---- removed entry23abc2, 324abc3, 425abc4, 526abc5, 627abc6, 0 <---- removed entry28abc7, 829abc8, 930abc9, 1031size : 8